Agents
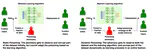
The rise of foundation models fine-tuned on human feedback from potentially untrusted users has increased the risk of adversarial data …
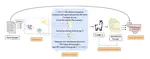
Existing approaches for low-resource text summarization primarily employ large language models (LLMs) like GPT-3 or GPT-4 at inference …
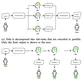
AI technologies are moving rapidly from research to production. With the popularity of Foundation Models (FMs) that generate text, …
Recent progress in large language models (LLMs) has focused on producing responses that meet human expectations and align with shared …

Multimodal AI has the potential to significantly enhance document-understanding tasks, such as processing receipts, understanding …

Data analytics is essential for extracting valuable insights from data that can assist organizations in making effective decisions. We …
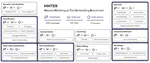
Text embeddings are typically evaluated on a narrow set of tasks, limited in terms of languages, domains, and task types. To circumvent …
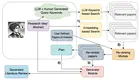
Literature reviews are an essential component of scientific research, but they remain time-intensive and challenging to write, …
Scalable Vector Graphics (SVGs) are vital for modern image rendering due to their scalability and versatility. Previous SVG generation …
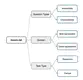
Abstention Ability (AA) is a critical aspect of Large Language Model (LLM) reliability, referring to an LLM’s capability to …