Multi-Modal Learning

One of the challenges in robotics is to enable robotic units with the reasoning capability that would be robust enough to execute …
Scalable Vector Graphics (SVGs) have become integral in modern image rendering and graphic design applications due to their infinite …
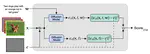
Text-conditioned image generation models have recently shown immense qualitative success using denoising diffusion processes. However, …

Large pre-trained models have proved to be remarkable zero- and (prompt-based) few-shot learners in unimodal vision and language tasks. …

The generative modeling landscape has experienced tremendous growth in recent years, particularly in generating natural images and art. …
Robots in many real-world settings have access to force/torque sensors in their gripper and tactile sensing is often necessary in tasks …

Metric-based meta-learning techniques have successfully been applied to few-shot classification problems. In this paper, we propose to …

For embodied agents to infer representations of the underlying 3D physical world they inhabit, they should efficiently combine …

Social media, as a major platform for communication and information exchange, is a rich repository of the opinions and sentiments of …

Allowing humans to interactively train artificial agents to understand language instructions is desirable for both practical and …