Multi-Modal Learning

Aligning visual features with language embeddings is a key challenge in vision-language models (VLMs). The performance of such models …

Multimodal AI has the potential to significantly enhance document-understanding tasks, such as processing receipts, understanding …

We introduce Visual Caption Restoration (VCR), a novel vision-language task that challenges models to accurately restore partially …
Scalable Vector Graphics (SVGs) are vital for modern image rendering due to their scalability and versatility. Previous SVG generation …

Vision and language models that can accurately understand both images and text are crucial for deeper document understanding. These …
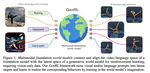
Learning generalist agents, able to solve multitudes of tasks in different domains is a long-standing problem. Reinforcement learning …

The ability to predict outcomes of interactions between embodied agents and objects is paramount in the robotic setting. While …

We introduce Visual Caption Restoration (VCR), a novel vision-language task that challenges models to accurately restore partially …
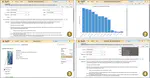
The ability of large language models (LLMs) to mimic human-like intelligence has led to a surge in LLM-based autonomous agents. Though …
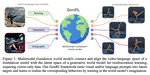
Learning generalist embodied agents, able to solve multitudes of tasks in different domains is a long-standing problem. Reinforcement …