Attack What Matters: Integrating Expert Insight and Automation in Threat-Model-Aligned Red Teaming
Abstract
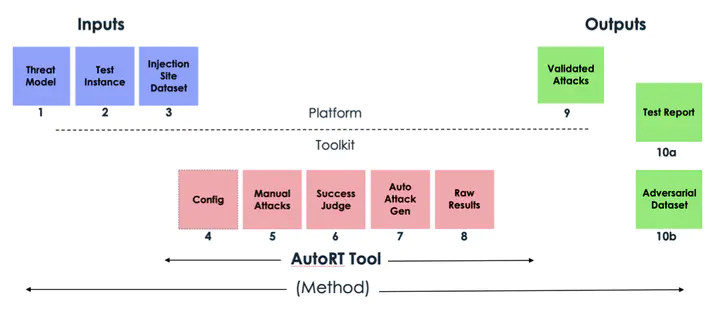
Prompt injection attacks target a key vulnerability in modern large language models: their inability to reliably distinguish between trusted and untrusted and potentially malicious instructions. This vulnerability has significant implications for customers using AI on the ServiceNow platform. We present an end-to-end Automated Red Teaming pipeline along with a case study on the Security Operations Now Assist. This case study highlights how prompt injections discovered by our tool can manipulate AI recommendations in SecOps. It includes examples of manipulated phishing incidents, demonstrating the vulnerability in production settings.
Kiarash Mohammadi
Applied Research Scientist
Applied Research Scientist at AI Research Deployment located at Montreal, QC, Canada.
Abhay Puri
Applied Research Scientist
Applied Research Scientist at AI Research Deployment located at Montreal, QC, Canada.
Georges Belanger Albarran
Applied Research Scientist
Applied Research Scientist at AI Research Deployment located at Montreal, QC, Canada.
Mihir Bansal
Machine Learning Engineer
Machine Learning Engineer at AI Research Deployment located at Santa Clara, CA, USA.
Marc-Etienne Brunet
Research Lead
Research Lead at AI Research Deployment located at Toronto, ON, Canada.
Jason Stanley
Head of AI Research Deployment
Head of AI Research Deployment at AI Research Deployment located at Montreal, QC, Canada.