Safety and Security
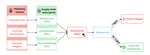
The practice of fine-tuning AI agents on data from their own interactions—such as web browsing or tool use—, while being a strong …

Leading language model (LM) providers like OpenAI and Anthropic allow customers to fine-tune frontier LMs for specific use cases. To …
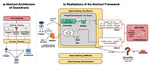
We present DoomArena, a security evaluation framework for AI agents. DoomArena is designed on three principles: 1) It is a …
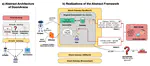
We present DoomArena, a security evaluation framework for AI agents. DoomArena is designed on three principles: 1) It is a …

The rise of AI agents that can use tools, browse the web and interact with computers on behalf of a user, has sparked strong interest …
Leading language model (LM) providers like OpenAI and Google offer fine-tuning APIs that allow customers to adapt LMs for specific use …