Efficient Learning

Merging parameter-efficient task experts has recently gained growing attention
as a way to build modular architectures that can be …
We take significant steps toward unifying autoregressive and diffusion-based sequence generation by extending the SEDD discrete …
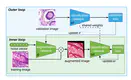
One of the main challenges faced when training a deep learning based model to classify histopathological images is the color and shape …
The advent of the transformer has sparked a quick growth in the size of language models, far outpacing hardware improvements. (Dense) …

Text-based dialogues are now widely used to solve real-world problems. In cases where solution strategies are already known, they can …
We introduce Breadth-First Pipeline Parallelism, a novel training schedule which optimizes the combination of pipeline and data …

Reinforcement learning (RL) aims at autonomously performing complex tasks. To this end, a reward signal is used to steer the learning …

Multi-Task Learning (MTL) networks have emerged as a promising method for transferring learned knowledge across different tasks. …