Theory of Machine Learning
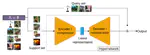
Both PAC-Bayesian and Sample Compress learning frameworks have been shown instrumental for deriving tight (non-vacuous) generalization …

We analyze the convergence of a novel policy gradient algorithm (referred to as SPMA) for multi-armed bandits and tabular Markov …

The sample compression theory provides generalization guarantees for predictors that can be fully defined using a subset of the …

Training large language models (LLMs) for pretraining or adapting to new tasks and domains has become increasingly critical as their …

We analyze the convergence of a novel policy gradient algorithm (referred to as SPMA) for multi-armed bandits and tabular Markov …
Reconstruction functions are pivotal in sample compression theory, a framework for deriving tight generalization bounds. From a small …

The sample compression theory provides generalization guarantees for predictors that can be fully defined using a subset of the …

Early Exiting (EE) is a promising technique for speeding up inference at the cost of limited performance loss. It adaptively allocates …

In statistical learning theory, a generalization bound usually involves a complexity measure imposed by the considered theoretical …
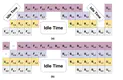
Optimizing large memory-intensive neural networks requires distributing its layers across multiple GPUs (referred to as model …