1
Deployed machine learning systems require some mechanism to detect out-of-distribution (OOD) inputs. Existing research mainly focuses …
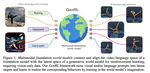
Learning generalist agents, able to solve multitudes of tasks in different domains is a long-standing problem. Reinforcement learning …
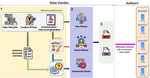
Large Language Models (LLMs) are trained on vast amounts of data, most of which is automatically scraped from the internet. This data …
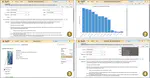
The ability of large language models (LLMs) to mimic human-like intelligence has led to a surge in LLM-based autonomous agents. Though …
This paper introduces a novel model compression approach through dynamic layer-specific pruning in Large Language Models (LLMs), …

Direct Preference Optimization (DPO) is an effective technique that leverages pairwise preference data (usually one chosen and rejected …

In-context learning (ICL) approaches typically leverage prompting to condition decoder-only language model generation on reference …

The BrowserGym ecosystem addresses the growing need for efficient evaluation and benchmarking of web agents, particularly those …
Forecasting is a critical task in decision making across various domains. While numerical data provides a foundation, it often lacks …
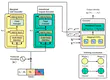
We introduce a new model for multivariate probabilistic time series prediction, designed to flexibly address a range of tasks including …