1
Large decoder-only language models (LLMs) are the state-of-the-art models on most of today’s NLP tasks and benchmarks. Yet, the …
Causal representation learning aims at identifying
high-level causal variables from perceptual data.
Most methods assume that all …

We study the use of large language model-based agents for interacting with software via web browsers. Unlike prior work, we focus on …
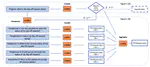
Large language models (LLM) have achieved remarkable success in natural language generation but lesser focus has been given to their …

Contemporary Large Language Models (LLMs) exhibit a high degree of code generation and comprehension capability. A particularly …

A common and fundamental limitation of Generative AI (GenAI) is its propensity to hallucinate. While large language models (LLM) have …
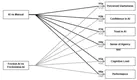
Incorporating ethical principles of human-centered AI, such as fostering human autonomy and mindful decision-making, challenges the …
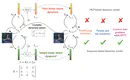
The accurate modeling of dynamics in interactive environments is critical for successful long-range prediction. Such a capability could …
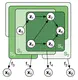
We present a unified framework for studying the identifiability of representations learned from simultaneously observed views, such as …
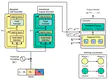
We introduce a new model for multivariate probabilistic time series prediction, designed to flexibly address a range of tasks including …