Apriel-SSM: Converting Pre-Trained Transformer LLMs Into Subquadratic Hybrid Models Through Iterative End-to-End Distillation
Abstract
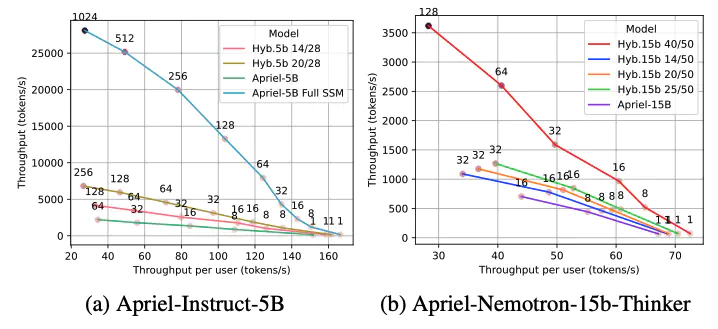
Large Language Models achieve their success through transformer architectures with attention mechanisms that compute token representations as weighted combinations of all preceding tokens. However, transformers suffer from quadratic complexity in the attention module and require caching key-value representations during inference, severely limiting throughput. State-space models (SSM) such as Mamba-2 offer linear complexity and constant memory footprint through recurrent paradigms with fixed-size hidden states. We propose converting pre-trained transformer LLMs into efficient hybrid architectures via end-to-end distillation. Applied to the recently released Apriel models (5B Apriel-Instruct and 15B Apriel-Nemotron-Thinker), our method demonstrates significant throughput improvements and increased maximum batch sizes with minimal performance degradation.
Oleksiy Ostapenko
Research Scientist
Research Scientist at AI Foundation Model located at Montreal, QC, Canada.
Luke Kumar
Applied Research Scientist
Applied Research Scientist at AI Research Deployment located at Toronto, ON, Canada.
Joel Lamy Poirier
Applied Research Scientist
Applied Research Scientist at AI Foundation Model located at Montreal, QC, Canada.
Sébastien Paquet
Research Manager
Research Manager at AI Research Deployment located at Montreal, QC, Canada.