Spécifiez une table des faits qui servira de source de données pour les répartitions. Appliquez des conditions pour spécifier les éléments de cette source de répartition.
Avant de commencer
Rôles requis : pa_data_collector, pa_admin ou administrateur. Le créateur de la source de répartition doit avoir accès à la table et à la colonne de référence utilisées par la source de l’indicateur.
Pourquoi et quand exécuter cette tâche
Utilisez toujours une table des faits avec un champ qui a une valeur unique pour chaque enregistrement, généralement l’ID système. Par exemple, la source de répartition Incident.Category tire ses éléments de la table Choix . Les éléments sont identifiés par le champ ID système . La source de répartition filtre les choix pour accéder à ceux qui figurent dans la table Incident , en anglais et qui ne sont pas inactifs. Conseil : Comme dans cet exemple, si vous utilisez Choix [sys_choice] pour la table de faits, placez des conditions sur les champs Table, Élément et Langue. Filtrez également les enregistrements inactifs.
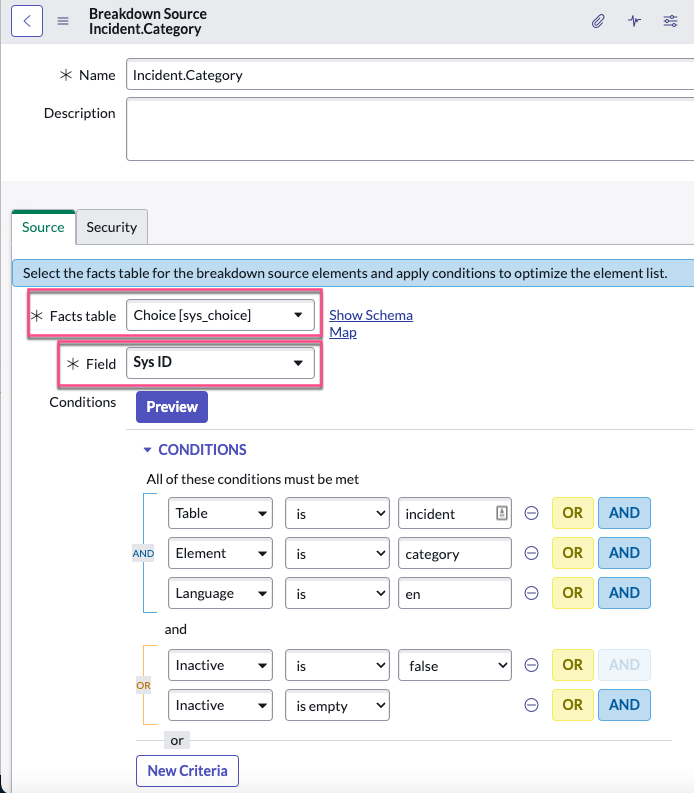
La source de répartition utilise les enregistrements suivants de la table Choix :

Remarque : La table Choix comprend tous les choix possibles de chaque table, c’est pourquoi elle comporte des colonnes Table et Élément. La plupart des autres tables de faits que vous utiliseriez comme source de répartition sont plus simples.
Procédure
-
Accédez à la et cliquez sur Nouveau.
-
Donnez à la source de répartition un nom significatif.
-
Ajoutez une description détaillée pour aider d’autres personnes à comprendre l’utilisation et le but de cette source de répartition et pour éviter de créer des doublons.
-
Pour la table de faits, sélectionnez la table dont la source de répartition obtient les éléments.
Par exemple, pour que la source de répartition spécifie des groupes d’utilisateurs en tant qu’éléments, sélectionnez
Groupe [sys_user_group].Avertissement : Ne modifiez pas la table de faits d'une source après avoir commencé à collecter des données. Si vous modifiez la table de faits, vous perdrez tous les scores historiques des indicateurs associés lors de la collecte de scores suivante.
-
Dans la table Champ , sélectionnez un champ qui contient une valeur unique pour chaque enregistrement.
Ce champ correspond généralement à l’ID système.
-
Définissez les conditions pour filtrer les éléments inutiles.
Si vous définissez le choix [sys_choice] comme table de faits, filtrez toujours sur la table, l’élément et la langue, et filtrez les enregistrements inactifs. Par exemple :
[Table] [est] [Incident] et
[Élément] [est] [Catégorie] et
[Langue] [est] [en] et
[Inactif] [est] [faux] ou
[Inactif] [est] [vide]
-
Pour voir combien d’enregistrements correspondent aux conditions sélectionnées, cliquez sur Aperçu.
- Facultatif :
Définissez les CONDITIONS DE LISTE CONNEXE pour inclure une relation avec une autre table dans le filtre.
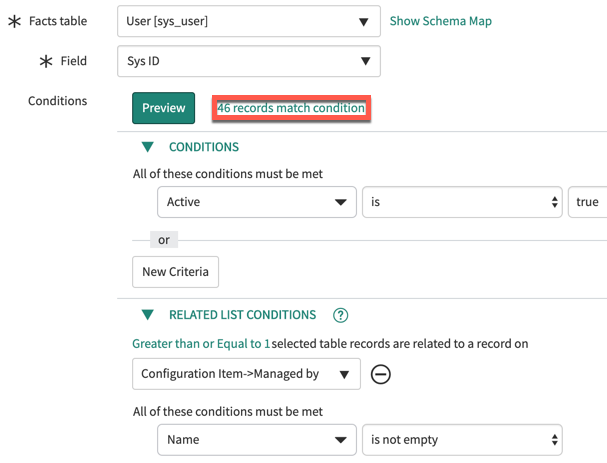
Par exemple, considérez une source de répartition pour les gestionnaires d’éléments de configuration (CI). La table de faits est Utilisateur [sys_user], mais la seule condition que vous pouvez appliquer à partir de cette table est de filtrer les utilisateurs actifs. Aucun champ de la table ne vous permet de sélectionner uniquement les utilisateurs qui sont des gestionnaires de CI. Vous obtenez des centaines de résultats.
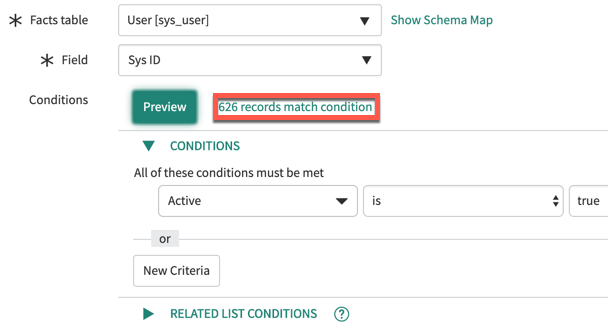
Si vous ajoutez une condition selon laquelle le nom figurant sur l’enregistrement Utilisateur doit correspondre à au moins une entrée dans la colonne Géré par de la table Élément de configuration [cmdb_ci], la source de répartition renvoie uniquement les utilisateurs qui sont des gestionnaires de CI.
- Facultatif :
Dans Étiquette pour sans correspondance, écrivez une étiquette personnalisée à utiliser lorsque la valeur d’un champ mappé sur un enregistrement source d’indicateur ne correspond à aucun élément de la source de répartition.
L’étiquette par défaut est Sans correspondance.
La source de répartition Incident.Category référence les enregistrements de la table Choix [sys_choices] où la valeur du champ Table est incident et la valeur du champ Élément est catégorie. La répartition par catégorie comprend un mappage depuis la source de répartition Incident.Category vers le champ Catégorie de la table Incidents [incident]. Si un enregistrement d’incident a une valeur nulle dans le champ Catégorie, la valeur lorsque vous appliquez la répartition de catégorie à cet enregistrement est Sans correspondance, par défaut.
-
Dans l’onglet Sécurité , définissez s’il faut exclure ou inclure des éléments de source de répartition par rôle en fonction des listes de sécurité des éléments.
Que faire ensuite
Créez des répartitions qui utilisent cette source de répartition. Vous pouvez ouvrir l’onglet Répartitions et cliquer sur Nouveau. Le formulaire Répartition s’ouvre, comme décrit dans .Créer une répartition automatisée Une fois que vous avez créé des répartitions qui utilisent cette source, ces répartitions sont répertoriées dans l’onglet Répartitions .